

필요한것
- 최신 Java JDK 8 (JavaFX 8 포함)
- Eclipse 4.6 또는 e(fx)clipse 플러그인을 포함한 그 이상 버전. 가장 쉬운 방법은 e(fx)clipse website에서 미리 포함되어 있는 버전을 받습니다. 다른 대안으로는 Eclipse에서 update site를 이용할 수 있습니다.
- Gluon이 제공하는 Scene Builder 8.0 (왜냐하면 Oracle은 오직 소스 코드 형태로만 제공하기 때문입니다.)
Eclipse 설정
- Eclipse가 JDK 8과 Scene Builder를 사용할 수 있게 해야 합니다:
- Eclipse Preferences를 열어 *Java | Installed JREs*를 찾습니다.
- *Add..*를 클릭한 후 *Standard VM*를 선택, JDK 8이 설치되어 있는 *디렉토리*를 고릅니다.
- 다른 JRE나 JDK를 삭제합니다. 그러면 JDK 8 하나만 남습니다.
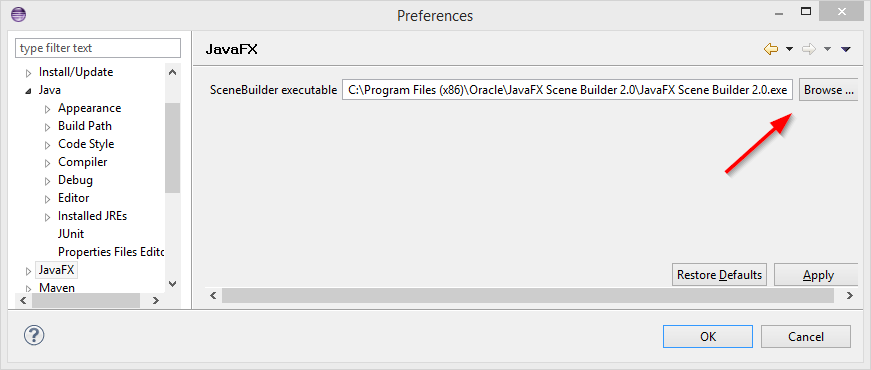
- *Java | Compiler*를 찾아 Compiler compliance level을 1.8로 설정합니다.
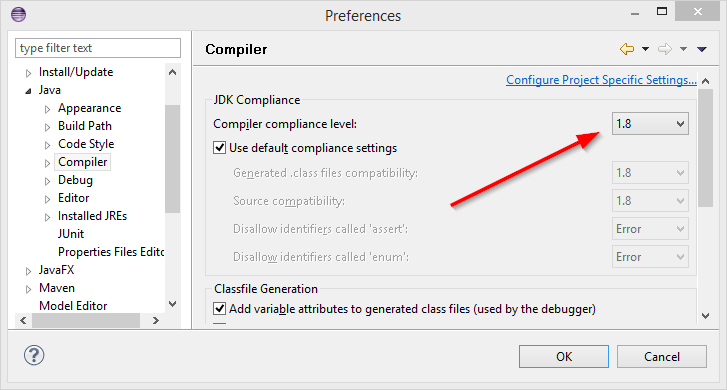
JavaFX 부분을 찾아 Scene Builder 실행 파일이 있는 경로를 지정합니다.
JavaFX 프로젝트 만들기
e(fx)clipse를 설치하고 나서 Eclipse에서 File | New | Other…, *JavaFX Project*를 고릅니다. 프로젝트 이름(예: AddressApp)을 작성한 다음, *Finish*를 클릭합니다.
자동으로 생성되는 application 패키지가 있다면 삭제하세요.
패키지 만들기
시작부터 우리는 좋은 소프트웨어 디자인 원칙을 따를 겁니다. 가장 중요한 원칙이 모델-뷰-컨트롤러입니다. 이에 따라 우리의 코드를 세 단위로 나누고 각 패키지를 만듭니다 (src 디렉토리에서 마우스 오른쪽 클릭 후 New… | Package 선택):
ch.makery.address- 컨트롤러 클래스의 대부분 (= 비즈니스 로직)ch.makery.address.model- 모델 클래스ch.makery.address.view- 뷰
참고: 우리의 뷰 패키지는 뷰와 직접 관련있는 컨트롤러 몇 가지도 포함할 겁니다. 이들을 뷰-컨트롤러라고 부르겠습니다.
FXML 레이아웃 파일 만들기
사용자 인터페이스를 만드는 방법은 2가지로 XML 파일을 이용하거나 모든 것을 Java로 프로그래밍하는 겁니다. 인터넷에서 찾아 보면 2가지 모두 사용하는 걸 발견할 수 있습니다. 우리는 XML (.fxml로 끝나는)을 이용할 겁니다. 저는 컨트롤러와 뷰를 서로 분리하는 것이 깔끔한 방법이라고 생각합니다. 게다가 Scene Builder를 사용하면 XML를 시각적으로 편집할 수 있습니다. 즉 우리는 XML을 직접 편집하지 않겠다는 말입니다.
뷰 패키지에 마우스 오른쪽 버튼을 클릭해서
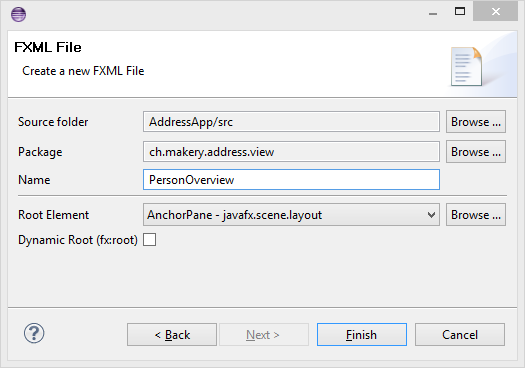
PersonOverview 라는 새로운 *FXML Document*를 만듭니다.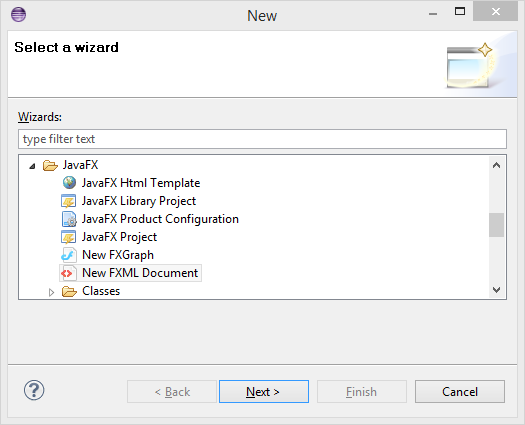
참고 사이트
댓글
댓글 쓰기