

공개키 암호화 방식 -[bigdata01,02,03,04]에 동시에 만듬
1.ssh key 만들기 [ssh-keygen -t rsa]
2. 아래와 같이 key 생성여부 확인

3.[cat id_rsa.pub >> authorized_keys] authorized_keys폴더에 key 암호를 복사
4.폴더 확인 id_rsa [private]와 id_rsa.pub [public]이 만들어짐
5 cat authorized_keys로 검색하면 아래와 같이 암호가 만든 폴더로 들어감.

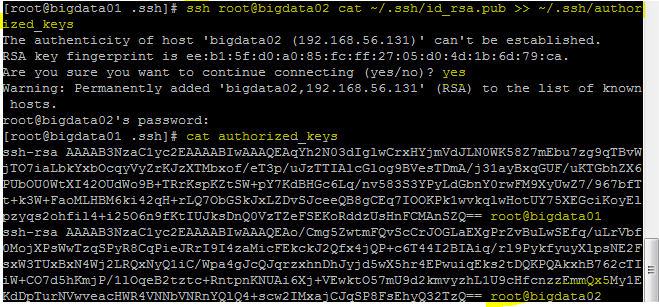
6.bigdata01에
[ssh root@bigdata02 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys]
를 입력
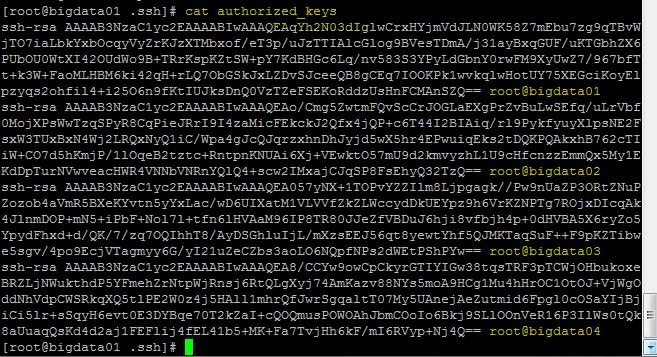
7.최종적으로 bigdata 02,03,04를 6번 같이 입력하여 authorized_keys 폴더에 전부 넣음
8.
[scp -rp authorized_keys root@bigdata02:~/.ssh/authorized_keys]
★scp= secure copy
bigdata 02, 03, 04 설정한 것을 복사해서 보냄.

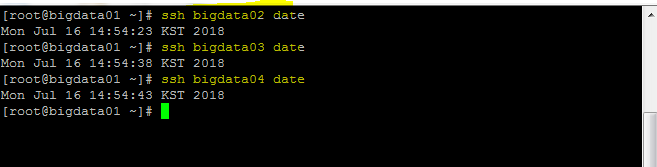
9.bidata01에서 [ssh bigdata02 date] 코드를 쳐서 아래와 같이 나오면 성공
댓글
댓글 쓰기